哈希洪水攻击¶
哈希洪水攻击(Hash-Flooding Attack)是一种拒绝服务攻击(Denial of Service),一旦后端接口存在合适的攻击面,攻击者就能轻松让整台服务器陷入瘫痪。
原理¶
在各种常用的数据结构里,有些数据结构的“平均运行时间”和“最差运行时间”会差很远,比如哈希表(Hash Table)。假设我们想要连续插入n个元素到哈希表中:
- 如果这些元素的键(Key)极少出现相同哈希值,这项任务就只需
的时间。
- 如果这些键频繁出现相同的哈希值(频繁发生碰撞),这项任务就需要
的时间。
2003年,Scott A. Crosby 和 Dan S. Wallach 两位研究人员发表了一篇论文:Denial of Service via Algorithmic Complexity Attacks。在这篇论文里他们首次提出:既然有些数据结构的最差运行时间这么废物,我们有没有可能通过算法上的漏洞,强行构造出一个最差情况,让服务器把全部的资源都浪费在处理这个最差情况上?
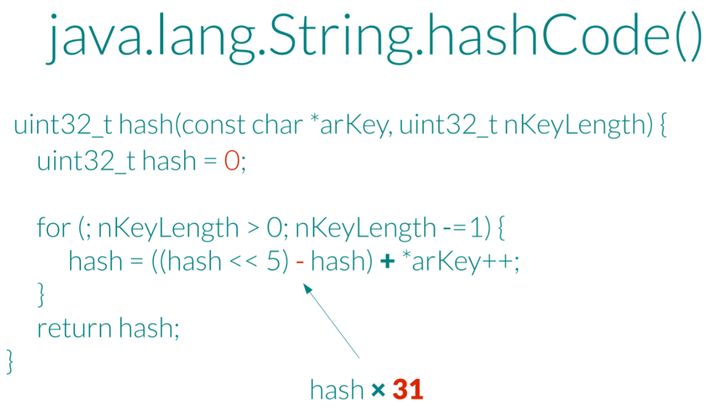

这样一来,只要构造出几万个同样哈希的字符串,把它们提交给服务器做哈希表, 就能用很低的成本将服务器打瘫了。
这个成本具体有多低呢?依2011年的实验数据,攻击一台基于Java(Tomcat)的服务器时,仅仅需要6KB/s的流量就能打瘫一颗 Intel i7 处理器,1GB/s的流量可以打瘫 100000 颗 Intel i7 处理器,性价比远超TCP半开连接等传统的拒绝服务攻击。
防御¶
首先介绍一个数学悖论,其之所以被称为悖论。不是因为其矛盾,而是因为其违背了大多数人的尝试。
生日悖论¶
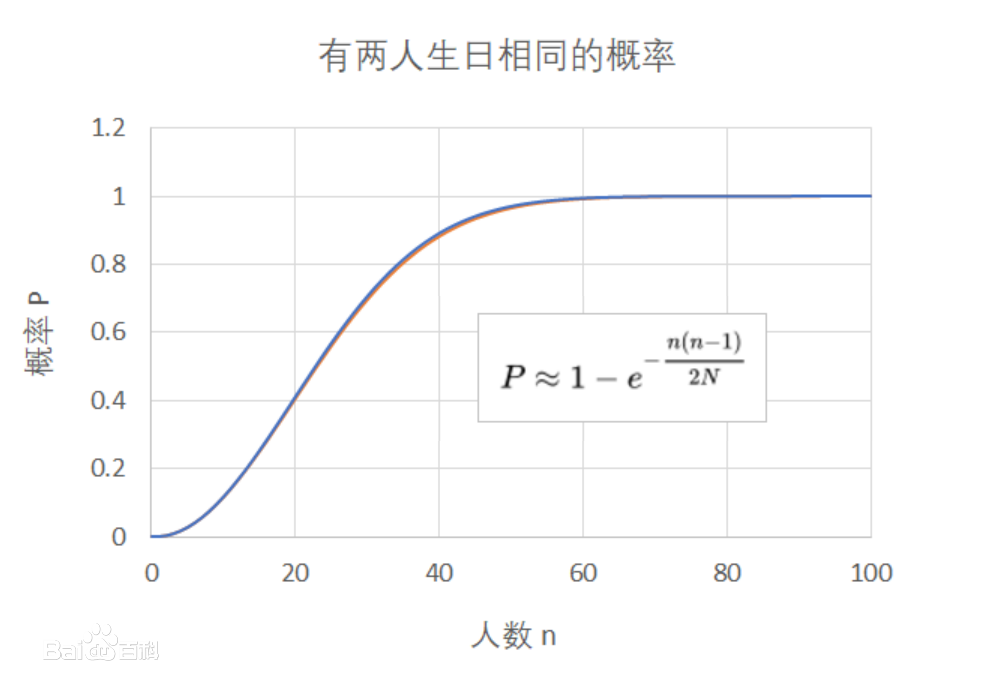
通过上图可以得知,大概在23个人的全体里就有两个人的生日完全相同,并随着人数越多,发生重复的概率越大。通过简单的公式可以看出这点:
其结果如表:
| n | 23 | 30 | 40 | 50 | 60 | 100 |
|---|---|---|---|---|---|---|
| P | 50.7% | 70.6% | 89.1% | 97.0% | 99.4% | 1-3.07*10^-7 |
可以看到 n = 100 远小于 N = 365 时,就已经几乎必然有一对同一天生日,所有人生日两两不同的概率仅一千万分之三。
**由生日悖论可知,通过设计更优秀的哈希算法不能让哈希值不发生碰撞。**因为一个哈希表的长度一般也就是几千个元素,根据生日悖论我们可以证明:不管你的算法设计得多么精妙,只要黑客掌握算法的所有细节,那就总能算出一组频繁碰撞的键来。
如果黑客不能掌握算法的所有细节,是不是就不能算出一组频繁碰撞的键,也就没法发动哈希洪水攻击?
换句话说,我们能不能在算法中加入一个黑客不知道的秘密参数?每建一张哈希表,我们就随机生成一个新的秘密参数。这样一来,即使是同样的内容,放在不同的表里也会产生完全不同的内存分配。这整个过程黑客完全无法预测,即使发生碰撞,也是小概率的巧合,而不是黑客在主动控制,攻击也就不可能成立了。
这个黑客不知道的秘密参数,我们现在称之为哈希种子(Hash Seed)。而这类使用哈希种子的哈希算法,我们称之为带密钥哈希算法(Keyed Hash Function)。
黑客一方的攻击目标,是想办法刺探出种子的值,或者在不知道种子的情况下构造出一组会碰撞的键来。而安全研究人员的目标,就是设计出更安全的带密钥哈希算法,保护好种子的安全,避免种子被黑客绕过。
这些年来,攻守双方在这个领域展开了激烈的攻防,来自Google、UIC等机构的众多研究人员设计了许多新的哈希函数:SipHash、MurmurHash、CityHash等等。这些算法不停地被推翻,不停地更新版本,到现在已经形成了一套稳定的算法标准,被众多编程语言和开源项目所采纳。
下面这张表来自SipHash官网,里面列举了众多采用SipHash-2-4算法的知名项目。其中Rust、Python、Ruby等语言更是把SipHash-2-4作为默认的哈希表实现方法,用这些语言编写的项目天生免疫哈希洪水攻击:

Java¶
很遗憾,Java并没有使用带密钥哈希算法。而是采用在JDK1.8之后,HashMap、LinkedHashMap和ConcurrentHashMap三个类引入了一套新的策略来处理哈希碰撞。
- 当一个位置存储的元素个数小于8个时,仍然使用链表存储。
- 当一个位置存储的元素个数大于等于8个时,改为使用平衡树来存储。
这样一来,就能保证最差的运行时间是了。
为什么要设立“8个元素”(TREEIFY threshold)这样一个限制呢?因为平衡树相比链表而言有着更高的开销,以及更散乱的内存布局(影响缓存命中率)。在正常情况下,哈希表的一个位置大约只会存储1~4个左右的元素,所以没有必要专门开一个平衡树来存储冲突的元素,对一些性能敏感的应用来说会造成显著的负面影响。
实际应用中究竟选用平衡树还是SipHash,完全是一件见仁见智的事情,两边没有哪个有显著的优势,实现起来也都不是很困难。



