窗口函数¶
什么是窗口函数¶
窗口函数,也叫OLAP函数(Online Anallytical Processing,联机分析处理),可以对数据库数据进行实时分析。
窗口函数的基本用法如下:
1 | <窗口函数> over (partition by <用户分组的列名> order by <用于排序的列名>) |
窗口函数可以放两种函数:
- 专用窗口函数
- 聚合函数
因为窗口函数是对where或者group by子句进行处理后的操作,所以窗口函数原则上只能写在select子句中
窗口函数的好处¶
窗口函数中的窗口表示的是范围的意思。
窗口函数实现的功能类似group by和order by。但是group by分组汇总会改变了表的行数,一行只有一个类别。而partition by和rank函数不会减少原表中的行数。
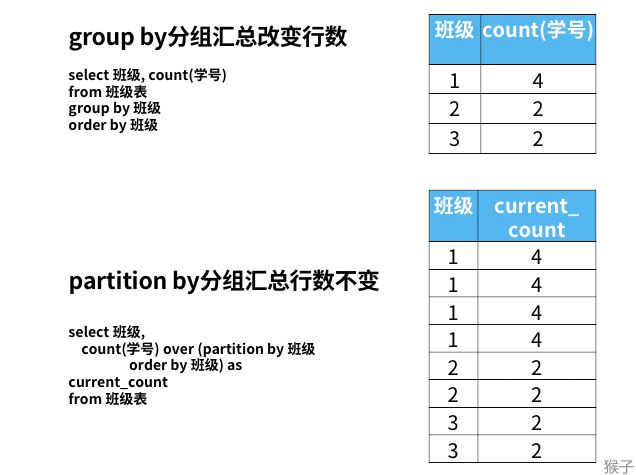
窗口函数中的order by只是决定窗口内的数据按什么顺序进行排序或计算,对最后返回结果的排列顺序并没有影响。
专业窗口函数¶
专业窗口函数主要为rank,dense_rank,row_number,其区别如下case所示:
1 | select *, |
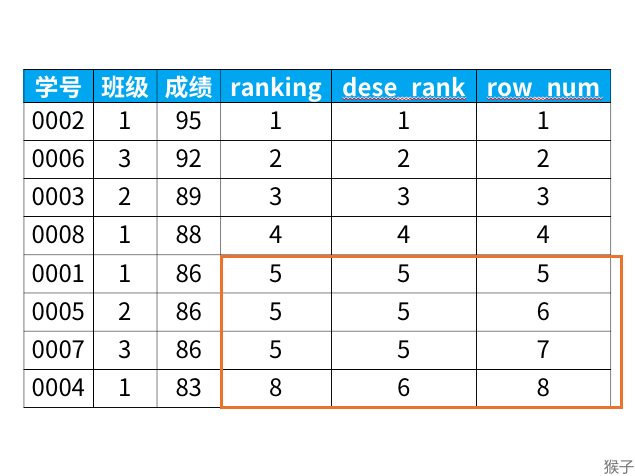
总结一下:
- rank函数:如果有并列名次的行,会占用下一名次的位置。
- dense_rank函数:如果有并列名次的行,不占用下一名次的位置。
- row_number函数:不考虑并列名次的情况。
在上述的这三个专用窗口函数中,函数后面的括号不需要任何参数,保持()空着就可以。
聚合函数作为窗口函数¶
聚和窗口函数和上面提到的专用窗口函数用法完全相同,只需要把聚合函数写在窗口函数的位置即可,但是函数后面括号里面不能为空,需要指定聚合的列名。
不仅是sum求和,平均、计数、最大最小值,也是同理,都是针对自身记录、以及自身记录之上的所有数据进行计算。
用处:聚合函数作为窗口函数,可以在每一行的数据里直观的看到,截止到本行数据,统计数据是多少(最大值、最小值等)。同时可以看出每一行数据,对整体统计数据的影响。
另外,在聚合窗口可以指定汇总范围,这个功能称之为框架。
自身+上1条记录:SUM(sale_price) over(order by product_id rows 1 preceding)
自身+下1条记录:SUM(sale_price) over(order by product_id rows 1 following)
自身+上1条记录+下2条记录:`SUM(sale_price) over(order by product_id rows between 1 preceding and 2 following)
CASE-WHEN¶
用法¶
case函数只返回第一个符合条件的值,剩下的case部分将会被自动忽略。如果省略了ELSE子句,则返回NULL。
简单case函数¶
1 | --简单case函数 |
case搜索函数¶
1 | case when sex = '1' then '男' |
sum和case结合使用¶
1 | select |
Hive多维分析函数¶
WITH CUBE¶
1 | GROUP BY 1,2 ... |
根据GROUP BY的字段的所有组合进行聚合
全维度聚合
聚合维度组合数
在presto中需要写成GROUP BY CUBE(1,2,...)
GROUPING SETS¶
1 | GROUP BY 1,2 ... |
在一个GROUP BY查询中,根据不同的字段组合进行聚合,等价于将不同字段的GROUP BY结果进行UNION ALL
自定义维度组合
聚合维度组合数N(N为sets中自定义的组合数)
WITH ROLLUP¶
1 | GROUP BY 1,2 ... |
是CUBE的子集,以GROUP BY最左侧的字段为主,从该字段开始进行层级聚合(相当于((),(1),(1,2)…))
左侧主维度组合
聚合维度组合数n+1
NVL¶
nvl(column,’空的替换值’)
排序函数¶
row_number()¶
遇到相同的排名index递增。
rank()¶
遇到相同的排名index一样,下一个不一样的记录之前的数量。
dense_rank()¶
遇到相同的排名index一样,下一个不一样的视为一个记录。
查询库大小¶
1 | select concat(round(sum(data_length/1024/1024),2),'MB') as data from information_schema.tables where table_schema='uoka'; |
datediff¶
全量表与增量表¶
参考资料¶
- 知乎,通俗易懂的学会:SQL窗口函数,2021
- 知乎,精益SQL —— “窗口函数”的正确食用方式,2019
- 博客园,SQL之case when then用法,2014
- 知乎,SQL之CASE WHEN用法详解,2019



